LLM-basierte OCR-Nachbearbeitung#
Feinlernziel(e) dieses Kapitels
Sie können die grundlegenden Herausforderungen beim Einsatz von Large Language Models für die OCR-Nachbearbeitung beschreiben.
Natürlich gibt es auch intelligentere Methoden zur Nachbearbeitung von OCR-Ergebnissen. Diese Methoden basieren auf datengesteuerten maschinellen Lerntechniken. Zum Beispiel können große Sprachmodelle manchmal sehr gut bei der Nachkorrektur von OCR-Ergebnissen abschneiden. Es ist jedoch wichtig, sich ihrer Risiken und Einschränkungen bewusst zu sein.
Große Sprachmodelle erfordern viele Ressourcen (Rechenressourcen, Energieressourcen, Speicherressourcen) zum Betrieb. Sie können nicht auf einem Personalcomputer ausgeführt werden und werden typischerweise als Dienst mit eingeschränktem Zugriff angeboten. Sie haben auch technische Beschränkungen hinsichtlich der Größe von Eingabe und Ausgabe. Daher könnte es eine große Herausforderung sein, einen großen Korpus zu verarbeiten.
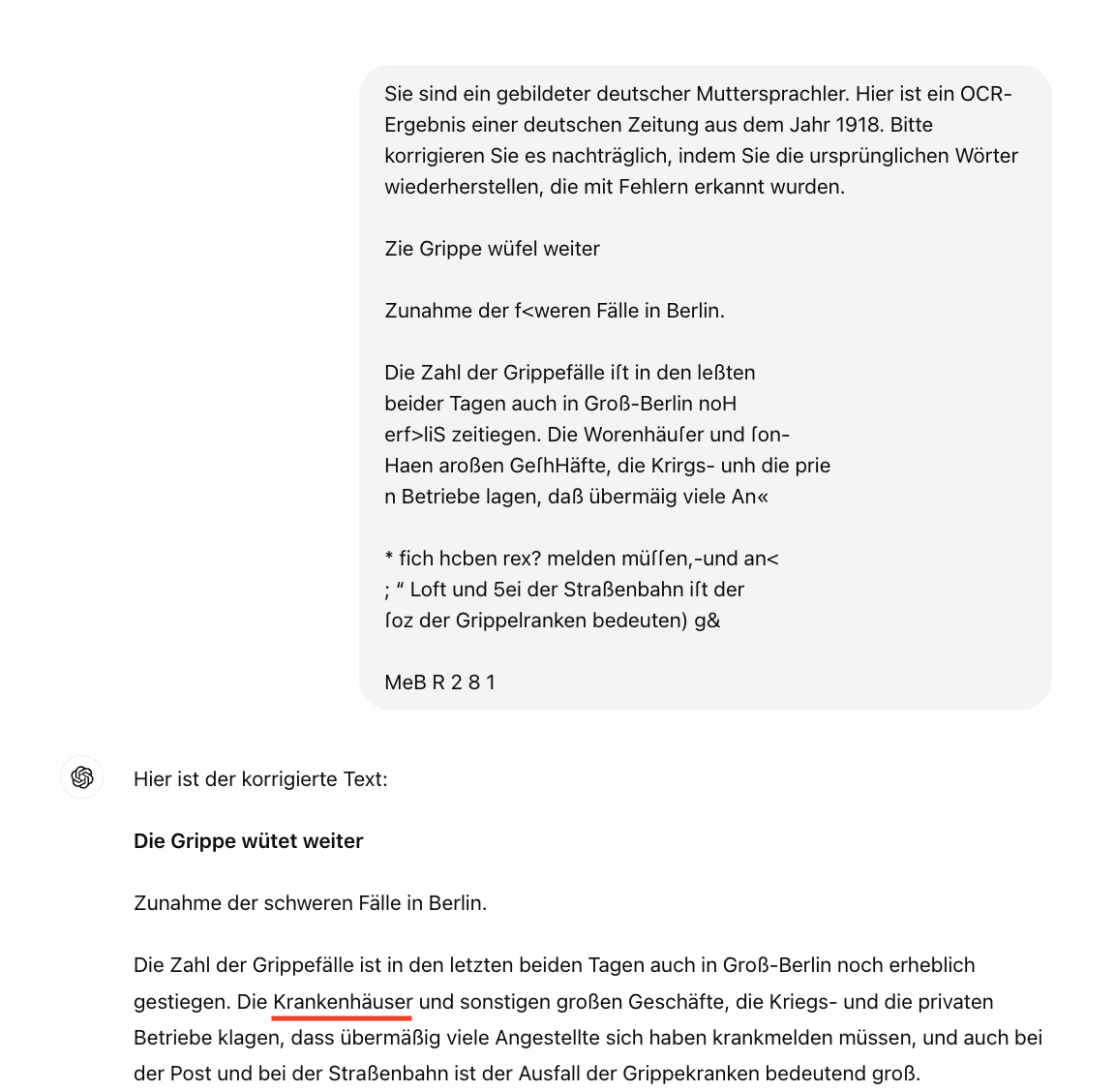
Ein ungenauer Prompt kann dazu führen, dass das Modell Text generiert, der im Original nicht vorhanden war. Im Folgenden verwenden wir GPT-4, um Beispiele zu generieren:
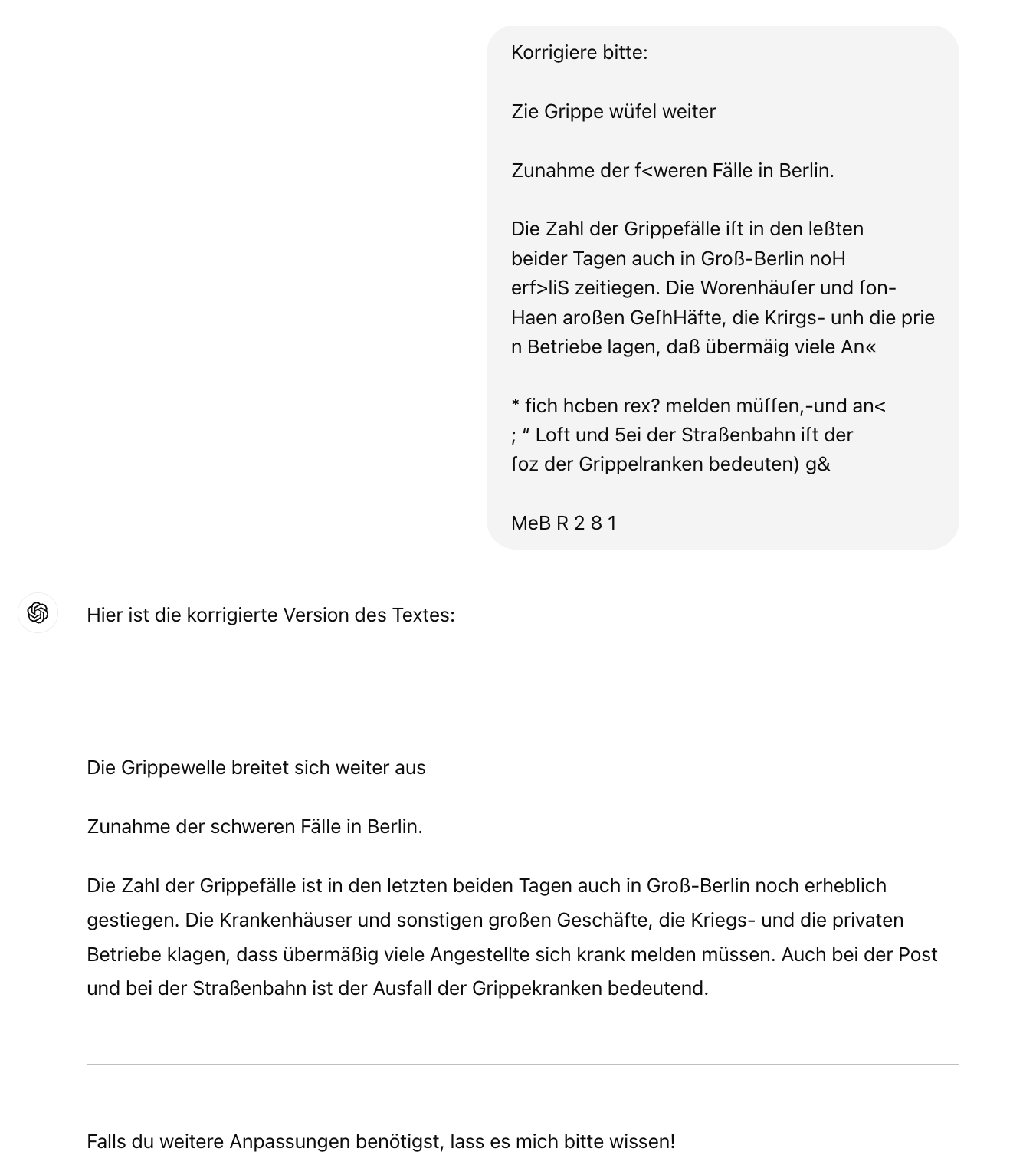
In diesem Fall haben wir das Modell einfach gebeten, zu „korrigieren“, und als Ergebnis erhielten wir einen Text, der erheblich verändert wurde. Dabei war unser Ziel eigentlich, nur die OCR-Fehler zu korrigieren, ohne den Originaltext zu ändern.
Versuchen Sie, detailliertere Anweisungen zu geben, um die gewünschten Ergebnisse zu erhalten.
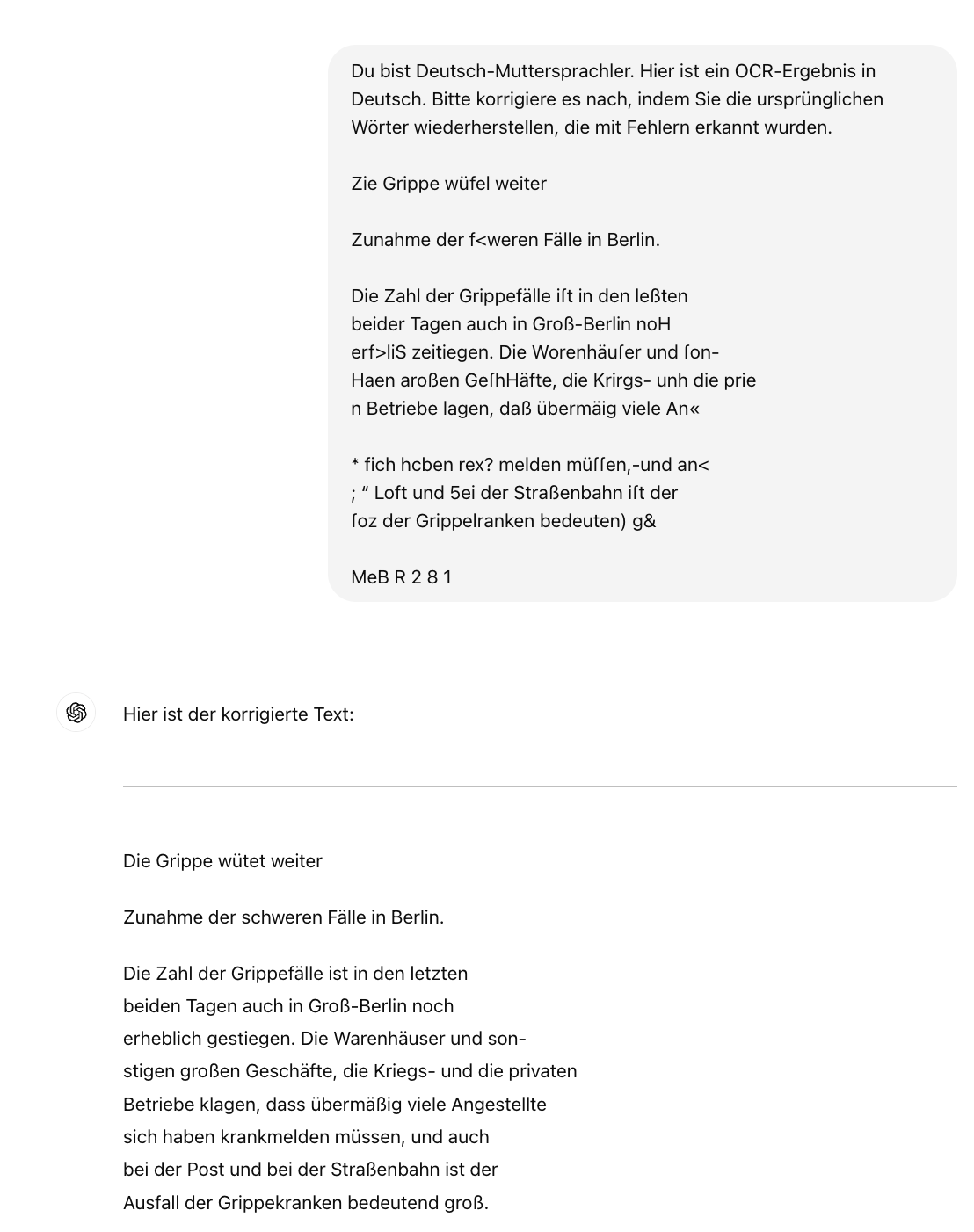
Sprachmodelle sind von Natur aus nicht deterministisch, sodass die Ergebnisse von Zeit zu Zeit variieren können. Sogar geringfügige und scheinbar harmlose Änderungen des Prompts können dazu führen, dass sie Halluzinationen erzeugen.