Häufigkeitenanalyse, Visualierung und KWIC#
Feinlernziel(e) dieses Kapitels
Sie verfügen über ein Grundverständnis des Konzepts des semantischen Feldes, können den Unterschied zwischen absoluten und relativen Häufigkeiten erklären und die Darstellungsmethoden des Liniendiagramms und der Key Word in Context (KWIC)-Anzeige interpretieren.
1. Forschungsfrage und Operationalisierung#
Wir gehen von folgender Forschungsfrage aus:
Forschungsfrage
Lassen sich für die Spanische Grippe 1918/1919 mit Fokus auf den Berliner Raum Muster in der öffentlichen Aufmerksamkeit ausmachen, die eine wellenartige Verlaufsform aufweisen?
Um diese mit quantitativen Methoden zu bearbeiten, wurde die Forschungsfrage zunächst wie folgt operationalisiert:
Die öffentliche Aufmerksamkeit im Berliner Raum wird durch ein Korpus von zwei Berliner Zeitungen gefasst.
Die Spanische Grippe wird durch ein semantisches Feld, das sich um das Wort “Grippe” kreist, untersucht.
Der Verlauf der öffentliche Aufmerksamkeit wird über die sich entwickelte Häufigkeit des Wortfelds untersucht. Eine erhöhte Häufigkeit deutet auf eine erhöhte Aufmerksamkeit hin.
2. Das semantische Feld der Spanischen Grippe#
2.1 Erläuterung: Semantisches Feld#
Das Ziel der Analyse ist es, zu quantifizieren, wie viel über die Spanische Grippe berichtet wird. Dafür sollen möglichst alle und nur die Textstellen erfasst werden, in denen die Spanische Grippe erwähnt wird. Eine Erwähnung liegt dann vor, wenn ein Wort vorkommt, das mit der Spanischen Grippe im Zusammenhang steht. Die Sammlung dieser Wörter nennen wir Semantisches Feld. Da die Wörter losgelöst von ihrem Kontext analysiert werden, sollten sie so gewählt sein, dass sie sich auf die Spanische Grippe und nur auf diese beziehen.
2.2 Erstellung des semantischen Felds#
Da Large Language Models sehr gut dazu in der Lage sind, semantisch ähnliche Wörter zu erzeugen, haben wir das semantische Feld mit Hilfe des Chatbots ChatGPT erstellt.
Spezifikation zur ChatGPT-Nutzung
Verwendete ChatGPT-Version: 1.2024.157 (1718053765), Modell: ChatGPT 4o
Prompt:
Du bist eine Digital Humanities-Forscherin mit Expertise im Bereich der Computerlinguistik. Du verfügst über umfassende Kenntnisse im Bereich der Semantik und des Text und Data Mining.
Bitte erstelle ein semantisches Feld zum Thema “Grippe”. Die Sprache ist deutsch. Bedingungen für die Wörter des semantischen Feldes sind.
die Wörter sollen Substantive sein;
Komposita sind erlaubt;:
die Wörter sollen sich am historischen Sprachgebrauch der Jahre 1918 und 1919 orientieren;
die Wörter sollen spezifisch für den Kontext “Grippe” sein;
die Wörter sollen nicht mehrdeutig sein, also noch Möglichkeit nicht in anderen semantischen Kontext vorkommen;
Als Resultat haben wir eine Liste mit 25 Nomen erhalten: Influenza, Grippe, Grippeepidemie, Grippewelle, Grippekranke, Grippepandemie, Lungenentzündung, Krankheitswelle, Seuchenzug, Krankheitsausbruch, Fieberanfall, Schüttelfrost, Atemnot, Körpererschöpfung, Genesungszeit, Ansteckungsgefahr, Seuchenschutz, Desinfektionsmittel, Schutzmaske, Krankenstation, Isolationsstation, Sanitätsdienst, Krankheitsverlauf, Todesopfer, Krankheitssymptom, Erkrankungsfall, Lungeninfektion
3. Häufigkeit als Analysemethode#
3.1 Warum die Häufigkeit analysieren?#
Die Analyse von Worthäufigkeiten ist sowohl in der Korpuslinguistik als auch in den Digital Humanities [p. 73] weit verbreitet. Für die Analyse von Inhaltswörtern (Nomen, Verben, Adjektive, Adverben) wird angenommen, dass ein hohes Vorkommen mit der Wichtigkeit der Wörter im Text korreliert. Besonders bei einer vergleichenden Analyse (etwa von zwei Zeitungen oder einem Thema über Zeit) ist die Häufigkeitsanalyse sinnvoll, da der Vergleich so quantisierbar wird.
3.2 Häufigkeit von Grippe#
Um die Wichtigkeit eines Themenfelds wie der Spanischen Grippe zu untersuchen, bietet es sich an, nicht nur das Vorkommen eines einzelnen Wortes wie “Grippe” zu untersuchen, sondern andere, mit Grippe im Zusammenhang stehende Wörter zu sammeln. Die Wörter werden in der Grundform angegeben, sodass sie mit den Lemmata im Text verglichen werden können. Für jedes Wort wird dann die Häufigkeit errechnet, diese nennt sich absolute Häufigkeit. Die absoluten Häufigkeiten werden addiert, sodass sich pro Text eine Zahl ergibt, die die Summe aller Häufigkeiten der Grippenbezogenen Wörter angibt.
Beispiel
Text: Die Grippe wütet weiter. Zunahme der schweren Fälle in Berlin. Die Zahl der Grippefälle ist in den letzten Tagen auch in Groß-Berlin noch erheblich gestiegen. Die Warenhäuser und sonstigen großen Geschäfte, die Kriegs- und die privaten Betriebe klagen, daß übermäßig viele Angestellte sich haben krank melden müssen und auch bei der Post und bei der Straßenbahn ist der Prozentsatz der Grippekranken deutlich gestiegen.
Lemmatisierter Text: der Grippe wüten weiter – Zunahme der schwer Fall in Berlin – der Zahl der Grippefall sein in der letzter Tag auch in Groß-Berlin noch erheblich steigen – der Warenhaus und sonstig groß Geschäft – der Krieg und der privat Betrieb klagen – daß übermäßig vieler angestellter sich haben krank melden müssen und auch bei der Post und bei der Straßenbahn sein der Prozentsatz der Grippekranke deutlich steigen –
Semantisches Feld “Grippe”: Grippe, Grippefall, Grippekranke
Häufigkeitsanalyse:
Wort |
Häufigkeit |
|---|---|
Grippe |
1 |
Grippefall |
1 |
Grippekranke |
1 |
Summierte Häufigkeit: 3
3.3 Vergleichbarkeit von Häufigkeiten#
Für die Vergleichbarkeit von Worthäufigkeiten in Texten ist wichtig, dass die Texte auch ansonsten vergleichbar sind. Stammen die Texte z. B. aus unterschiedlichen Zeiträumen müssten ggf. zeitspezifische semantische Felder erstellt werden, um für den Sprachwandel Rechnung zu tragen. Auch sollten die Texte eine ähnliche Länge haben, sodass eine erhöhte Häufigkeit tatsächlich auf eine erhöhte Wichtigkeit zurückgeführt werden kann. Wenn Texte verschieden lang sind, sollten die Häufigkeiten normalisiert werden, das heißt sie werden in Bezug zur Textlänge gesetzt. Dafür wird die absolute Häufigkeit durch die Textlänge dividiert, daraus ergibt sich die relative Frequenz. Die relative Frequenz des semantischen Felds “Grippe” kann als Anteil der Grippewörter am Gesamttext gesehen werden.
Beispiel
Der Beispieltext besteht aus insgesamt 69 Wörter, davon sind 4 Wörter in dem semantischen Feld “Grippe” vorhanden. Daraus ergibt sich folgende Rechnung:
\( f = {4 \over 69} = {0.05797101449} \)$.
Das heißt: Jedes zwangstigste Wort im Text steht im Zusammenhang mit der Spanischen Grippe.
3.4 Analyse des gesamten Korpus#
Um den Verlauf der Aufmerksamkeit nachzuvollziehen, wird für jeden Text im Korpus die relative Frequenz des semantischen Felds “Grippe” berechnet und in einer Tabelle gespeichert. Die Frequenzen werden dann über die Zeit verglichen.
Beispiel
Zeitung |
Relative Häufigkeit |
Tag |
Monat |
Jahr |
|---|---|---|---|---|
Grippe |
1 |
|||
Grippefall |
1 |
|||
Grippekranke |
1 |
|||
krank |
1 |
Um Muster zu erkennen, ist es sinnvoll die erhobenen Häufigkeiten in größere Zeitabschnitte zu unterteilen, wie z.B. Wochen oder Monate. Dafür werden sowohl die absoluten Häufigkeiten als auch die Textlängen in dem ausgewählten Zeitraum addiert, sodass auf dieser Basis die relative Häufigkeit für den Zeitraum berechnet werden kann.
Durchschnitt von relativen Häufigkeiten
Eine zweite Möglichkeit, die Häufigkeiten über eine Zeitraum zusammenzufassen, bestünde darin, den Durchschnitt der Häufigkeiten zu nehmen. Diese Methode ist davon von schwankenden Textlängen an verschiedenen Tagen abhängig. Eine Folge davon wäre, dass Tage mit kurzen Texten und einer hohen Anzahl an Grippewörtern den Durchschnitt stark in die Höhe ziehen würden, obwohl die absolute Anzahl an Wörtern geringer ist als an Tagen, für die längere Texte vorliegen.
Tag |
Absolute Häufigkeit |
Textlänge |
|---|---|---|
1 |
20 |
500 |
2 |
5 |
100 |
3 |
15 |
600 |
Alle Häufigkeiten addieren und durch die Summe der Textlängen teilen: \( {{20 + 5 + 15} \over {500 + 100 + 600}} = {{40} \over {1200}} = {0.033}\)
Die relative Häufigkeiten addieren und durch die Anzahl an Tagen teilen: \( {{{20 \over 500} + {5 \over 100} + {15 \over 600}} \over 3} = {{0.04 + 0.05 + 0.025} \over 3} = 0.038\)
Mit der zweiten Methode ist die relative Häufigkeit um 0.005 Prozentpunkte höher.
4. Visuelle Darstellung#
Im diesen Schritt werden die extrahierten absoluten oder relativen Häufigkeiten mit einem Liniendiagramm visualisert. Liniendiagramme eignen sich gut, um zeitliche Verläufe darzustellen, da lokale und globale Minima und Maxima leicht erkennbar sind und sie die Kontinuität der Daten unterstreichen.
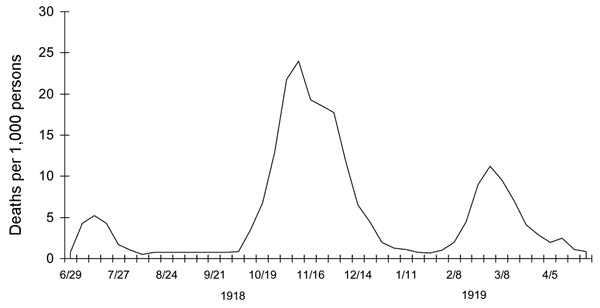
Fig. 10 Drei Wellen der Spanischen Grippe im Vereinigten Königreich. Quelle: [Taubenberger and Morens, 2006]#
Das Liniendiagramm (siehe Abbildung oben), das wir als Orientierungsgröße für ein wellenartiges Muster nehmen, zeigt den zeitlichen Verlauf der durch die Spanische Grippe verursachten Todesfälle in Großbritannien. Die Ticks auf der x-Achse zeigen die Wochen und die Beschriftung die Monate an (in Form von Monat/Tag). In einer weiteren Beschriftung wird auf das Jahr verwiesen. Da die einzelnen Erhebungen (z. B. das erste lokale Minimum zwischen Juni und Juli 1918) granularer sind als die angegeben Monate, können wir annehmen, dass die Daten wochenweise zusammengefasst wurden. Die y-Achse gibt, wie die Beschriftung sagt, die Tode pro 1.000 Personen an. Wir erstellen eine ähnliche Visualierung mit dem Unterschied, dass die y-Achse die relative Worthäufigkeit angibt.
Die Häufigkeiten über Zeit ließen sich auch in einem Balkendiagramm darstellen. Diese sind nützlich, um Häufigkeiten in diskreten Zeitintervallen zu visualisieren, sie eignen sich aber weniger gut, um eine zeitliche Entwicklung zu zeigen.
5. Keyword in Context (KWIC)#
5.1 Was ist KWIC?#
Die Keyword in Context (KWIC)-Darstellung basiert auf der Suche eines oder meherer Worte oder einer Phrase innerhalb eines Korpus und zeigt den gesuchten Term sowie den textuellen Kontext des Terms an. Es kann dabei definiert werden, wie groß der Kontext ist (z. B. 5 Wörter, ein Satz, etc.). Wie in der Tabelle zu sehen ist, hat die Darstellung die Form einer Tabelle mit drei Spalten: der Kontext auf der linken Seite, der gesuchte Term (meist farblich hervorgehoben), der Kontekt auf der rechten Seite. Zusätzlich können noch Metadaten gegeben sein, wie die Quelle (wenn in einem Korpus gesucht wird) oder das Datum.
Linker Kontext |
Suchterm |
Rechter Kontext |
Datum |
|---|---|---|---|
- Zahn- Praxis Klömpen Beize n a Een naa… |
Grippe |
DIRE Tr beite wi |
1918-12 |
Am Dienstag , 27. Auguſt , abends , Verffötb i… |
Grippe |
ung en Grippe in „ treuen Pfichterſülung fürs … |
1918-09 |
Am 19. Okiober .d . 45 , Wir büten voten , … |
Grippe |
3. verſchied in einem Feld- 8 lazarett info… |
1918-10 |
5.2 Der Gebrauch von KWIC#
Die KWIC-Darstellung bildet eine Brücke von der quantitativen zur qualitativen Analyse, da die Grundlage der Häufigkeitenanalyse genauer in Betracht genommen werden kann. Die Kontexte geben eine Überblick über den Gebrauch des Wortes und bieten so die Möglichkeit, Muster im Wortgebrauch festzustellen. Die zusätzlichen Metadaten erlauben es, in interessanten oder in Zweifelsfällen einen Blick in die Quelle zu werfen und so den Analysekontext zu erweitern.
Mit Hilfe der Darstellung kann außerdem die Annahme überprüft werden, dass sich die Wörter im semantischen Feld “Grippe” tatsächlich auf die Grippe beziehen. Das semantische Feld kann in einem iterativen Prozess manuell verbessert werden, indem mehrdeutige Wörter, die häufig nicht auf die Grippe verweisen, aus dem Feld gelöscht werden und Wörter, die häufig im Kontext der Grippe vorkommen, aber nicht Teil des Felds sind, hinzugefügt werden.
6. Zusammenfassung und nächste Schritte#
Mit diesem Kapitel sind wir zur Operationalisierung der Forschungsfrage zurückgekehrt. Es wurde herausgestellt, dass die Grippe durch ein semantisches Feld untersucht und wie dieses erstellt wurde. Dann wurde die Methode der Häufigkeitenanalyse vorgestellt und in die Visualierung der Häufigkeiten eingeführt. Zum Schluss wurde die Darstellung Keyword in Context erklärt und der Gebrauch erläutert.
Im nächsten Abschnitt wird die Häufigkeitsanalyse durchgeführt, dabei besteht die Möglichkeit mit einem eigens erstellten semantischen Feld zu arbeiten. Die berchneten Häufikeiten werden dann in einem Liniendiagramm visualisiert. Darauffolgend gibt es die Möglichkeit, Suchterme für die KWIC-Darstellung einzugeben und sich so einen tieferen Einblick in die Analyse zu verschaffen. Abschließend folgt ein Resümee.